当下人工智能研究火热,对于GPU卡的需求也越来越大,越来越多的AI从业者与爱好者,开始选择租用一台GPU云服务器。GPU云服务器,简单来说,就是可以通过网络获取算力资源、存储资源和网络资源等的虚拟服务器,它用起来灵活便捷,能够快速部署,即开即用,支持多种应用场景,与自建算力集群相比,无需投入大量人力物力财力去购买和维护算力集群,算力需求方可以最大限度地根据项目需求快速扩展或缩减资源,有效降低成本。
在厚德云的算力服务平台,不仅有 L20,更有全系算力资源(3090、4090、A10、L20、T4、L40、A100、A800、H100、H800等,支持多种方式的灵活租赁),除了算力租赁之外,厚德云还为多行业提供深度定制的算力集群解决方案,配备专业的技术支持,社区和生态的支持,为用户提供真正的算力生态,以生态赋能服务,满足不同用户的不同需求。
现在,L20算力资源已经可以在厚德云灵活租赁,L20是英伟达推出的专业级图形处理单元(GPU),基于先进的 Ada Lovelace 架构设计,专为高性能计算和图形处理任务而打造,在自然语言处理、计算机视觉、机器学习、数据分析等场景都有着不俗的表现。
那么,L20的性能到底怎样?我们先从几个参数来一一解读。
L20显存:48GB
显存,即显卡内存,主要用来存放数据模型,决定了我们一次读入显卡进行运算的数据多少(batch size)和我们能够搭建的模型大小(网络层数、单元数),是对深度学习人员来说很重要的指标,简单来说,显存越大越好。
L20的显存是48GB,相较于4090,大显存是L20的优势之一。
L20架构:Ada Lovelace
在显卡流处理器、核心频率等条件相同的情况下,不同款的GPU可能采用不同设计架构,不同的设计架构间的性能差距还是不小的,显卡架构性能排序为:Ada Lovelace > Ampere > Turing > Volta > Pascal > Maxwell > Kepler > Fermi > Tesla。
L20CUDA核心数量:10240
CUDA是NVIDIA推出的统一计算架构,NVIDIA几乎每款GPU都有CUDA核心,CUDA核心是每一个GPU始终执行一次值乘法运算,一般来说,同等计算架构下,CUDA核心数越高,计算能力会递增,能够更好地处理并行运算。
L20核心频率:1440~2520MHz
核心频率表示 GPU 的工作速度,即每秒钟处理的指令数,较高的核心频率意味着 GPU 能够更快地处理图像和图形数据,提供更流畅的图像渲染和更快的计算速度。
L20 的基础频率为 1440MHz,在运行过程中,在特定的工作负载和散热条件允许的情况下,可以提升到 2520MHz。
L20功耗:275W
功耗和散热保证了 GPU 在高负载情况下的稳定性和可靠性,低功耗和高散热性能也可以降低机箱温度,减少电费开支。
L20的功耗为275W,L40和V100的功耗在300W左右,4090的功耗则在450W。
L20浮点性能:FP32 59.35TFLOPS
浮点性能,是衡量计算机处理浮点运算能力的一个指标。通常用每秒浮点运算次数(缩写为 FLOPS)来表示,浮点性能越高,就能够更快地处理计算任务。
单精度(FP32)、半精度(FP16)、双精度(FP64)都是用于表示浮点数的不同精度标准,分别以 32 位、16 位、64 位存储。
以上就是一些主要的显卡参数解读,总的来说,判断一个GPU卡的性能,可以从显存、架构、CUDA核心数量、核心频率、单精度浮点性能、半精度浮点性能、功耗与散热、兼容性与驱动支持等方面考虑,同时也要考虑你要用GPU卡来做什么任务,有些卡在训练方面表现得更好,有些卡则更适合做推理任务,除了这些,还要看CPU、内存、磁盘性能等等,最后根据你的预算选一款能最大程度满足你的使用需求的GPU卡。
有了这个思路,我们再来看下面的选型指南,就好理解多了。
1、选择 CPU
GPU 与 CPU 的匹配:首先,要考虑 GPU 与 CPU 之间的匹配性。不同型号的 GPU 对 CPU 的要求不同,因此需要选择与所使用的 GPU 相匹配的 CPU 。通常,GPU的规格中会标明所需的最低 CPU 要求,可以参考这个要求来选择合适的 CPU 。
处理器核心数:其次,要考虑处理器的核心数。CPU 的核心数越多,可以同时处理的线程就越多,从而提高计算性能。对于需要进行大规模并行计算的应用,如机器学习、深度学习等,选择核心数较多的 CPU 能够更好地发挥 GPU 的计算能力。
频率与缓存大小:除了核心数外,CPU 的频率和缓存大小也会对计算性能产生影响。频率越高,计算速度越快;而缓存越大,能够存储的数据量就越多,从而减少对内存的读写次数,提高计算效率。
平台兼容性:此外,还需要考虑 GPU 云服务器所采用的平台。不同的平台对 CPU 的要求也有所不同,因此需要选择与所用平台兼容的 CPU 。
功耗与散热:最后,还需要考虑 CPU 的功耗和散热情况。高性能的 CPU 通常会消耗更多的功耗,产生更多的热量,因此需要确保服务器的散热系统能够有效降低温度并保证稳定运行。
综上所述,选择 GPU 云服务器的 CPU 时,应考虑与 GPU 的匹配性、核心数、频率与缓存大小、平台兼容性以及功耗与散热情况等因素。根据不同的应用需求和预算限制,选择最适合自己的 GPU 云服务器的 CPU 。
2、选择 GPU
将 GPU 架构大致分为五类的方式可能因人而异,但基于 NVIDIA 的 GPU 发展历程,我们可以这样归纳:
传统图形处理架构:这是指那些专注于图形渲染和早期计算功能的架构,比如 NVIDIA 的 Fermi 架构之前的产品。这类架构主要关注于游戏和基本的图形应用。
通用计算架构:以 Fermi 架构为代表,标志着 GPU 开始广泛应用于通用计算领域。 Fermi 架构引入了完整的 GPU 计算架构,并加强了双精度支持,使得 GPU 在科学计算和工程仿真等领域发挥重要作用。
高效能计算架构:如 Kepler、Maxwell、Pascal 等架构,这些架构在提高效能的同时,也引入了诸如 GPU Direct 等技术,进一步增强了 GPU 在高性能计算 (HPC) 领域的应用能力。
人工智能与深度学习架构:Volta 架构引入了 Tensor Cores,专门用于加速深度学习和 AI 计算任务。随后的 Turing 架构继续推进AI计算能力,并引入了 RT Cores 支持实时光线追踪技术。
现代综合计算架构:包括 Ampere 及其后续的 Ada Lovelace 架构,这些架构不仅进一步提升了 AI 和光线追踪性能,还在图形计算、游戏体验以及专业计算领域达到了新的高度。
需要注意的是,上述分类是基于 NVIDIA GPU 的发展历程,而 GPU 市场中还有其他重要的玩家,如 AMD 和Intel,它们也有自己独特的 GPU 架构和技术路线。此外,随着技术的快速发展,新的架构和类别可能还会不断涌现。一般我们认为模型的一次训练应当在 24 小时内完成,这样隔天就能训练改进之后的模型。以下是选择多 GPU 的一些建议:
1块 GPU。适合一些数据集较小的训练任务,如 Pascal VOC 等。
2块 GPU。同单块 GPU,但是您可以一次跑两组参数或者把Batchsize扩大。
4块 GPU。适合一些中等数据集的训练任务,如 MS COCO 等。
8块 GPU。经典永流传的配置!适合各种训练任务,也非常方便复现论文结果。
3、选择内存
内存在充足的情况下一般不影响性能,但是由于实例相比本地电脑对内存的使用有更严格的上限限制(本地电脑内存不足会使用硬盘虚拟内存,影响是速度下降),比如租用的实例分配的内存是 128 GB ,程序在训练时最后将要使用 129 GB ,此时超过限制的这一时刻进程会被系统 Kill 导致程序中断,因此如果对内存的容量要求大,请选择分配内存更多的主机或者租用多 GPU 实例。如果不确定内存的使用,那么可以在实例监控中观察内存使用情况。
4、附:GPU型号简介
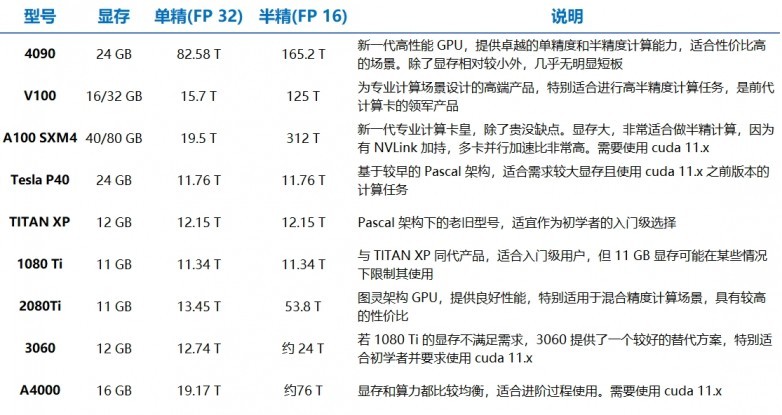
更多GPU选型指南,尽在厚德云官网「帮助中心」

「免责声明」:以上页面展示信息由第三方发布,目的在于传播更多信息,与本网站立场无关。我们不保证该信息(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关信息并未经过本网站证实,不对您构成任何投资建议,据此操作,风险自担,以上网页呈现的图片均为自发上传,如发生图片侵权行为与我们无关,如有请直接微信联系g1002718958。
