作为全球领先的云计算服务提供商,天翼云依托其广泛的基础设施和丰富的行业经验,与Intel等合作伙伴在软硬件多个领域展开了深入合作,致力于为用户提供更高效、更智能、更具弹性的计算解决方案。生态合作不仅加速了天翼云计算基础设施的升级,也为云计算生态系统的创新奠定了坚实的基础。为打造更加卓越的上云体验,天翼云不断升级弹性计算服务,基于Intel 全新第六代GNR至强处理器,在弹性云主机,聚合计算以及高性能计算等方面均得到算力全新升级,助力各行各业数字化转型。
天翼云第九代弹性云主机(ECS)
搭载最新GNR处理器的自研第九代弹性云主机,实现了全场景性能升级,其卓越的性能、灵活的扩展性和安全稳定的服务无疑将为用户带来更优质、更高效的云计算体验。与上一代产品相比,其在不同主流工作负载的性能提升高达2倍以上,能效提升高达40%~110%。在比较常见的服务器使用率40%的情况下,能效最高可提升90%。基于特定强化内存MRDIMM,数据传输速率高达8800MT/s,内存带宽提升高达2.3倍,在科学计算与AI应用中可带来30%以上的性能提升。
此外,第九代弹性云主机将内置多种加速引擎,AMX(Advanced Matrix Extensions,高级矩阵扩展技术)提升基于CPU的深度学习训练和推理性能,除INT8(8位整数数据类型)和BF16(16位浮点数格式)外,进一步支持基于FP16(16位半精度浮点数格式)的模型,AVX-512指令集(Advanced Vector Extensions 512)有助于提高每时钟周期处理的数据量,QAT(QuickAssist Technology,数据流加速技术)支持批量加密和压缩,IAA(In-Memory Analytics Accelerator,数据分析加速器)卸载内存压缩和解压缩、扫描及循环冗余校验。提升基于CPU的深度学习训练和推理性能,助力计算与数据密集型负载,对于需要处理复杂计算任务的大型企业,从数据分析到机器学习模型训练,都能提供强有力的支持。
同时,第九代弹性云主机基于硬件强化的安全特性,提供虚机层面的硬件隔离,无需复杂的应用改造,实现更严格的加密隔离机制,更好地保护敏感企业数据,性能损耗极低,保证业务无损运行,能更好地覆盖金融、政企等核心应用场景。
天翼云聚合计算(HAC)
天翼云聚合计算是一种基于高速总线互联网络和分离池化数据中心硬件架构的全新理念,聚合计算平台是天翼云以此为基础打造的下一代云基础设施平台。平台产品包括:超聚合计算服务器,内存即服务,池化计算加速。天翼云聚合计算旨在大数据、基因分析、芯片设计(EDA)、数据库、AI 训练等大计算应用场景,为用户提供超大规格、超高性能、可灵活扩展的下一代计算服务。
基于最新GNR处理器提供的出色性能和对CXL2.0内存池技术的强大支持,天翼云推出了“超聚合计算服务器”产品,专为打破数据中心“内存墙”而设计。超聚合计算服务器能够为内存密集型的大数据及AI应用任务提供突破性的优化加速与性能提升,确保用户在复杂计算场景下获得卓越的处理能力和效率。
在天翼云超聚合计算服务器产品中,CXL2.0高速互联协议下的内存池访问性能显著提升,远端内存访问延时可低至百纳秒级,几乎与本地内存的访问延时相当。超聚合计算服务器的有效访问带宽最高可达数百GB/s,并能够根据线路数与内存池容量灵活调节,为数据密集型工作场景提供卓越的吞吐量保障。
特别是在GNR处理器的Intel Flat Memory Mode的支持下,多个数据库和大数据应用场景中CXL远端内存的访问性能已接近本地DRAM水平。与传统EMR平台相比,在GNR平台上运行Spark、Hive等工作负载时,天翼云超聚合计算服务器能够实现2-4倍的吞吐量提升,显著减少执行时间。此外,在AI/ML训练场景中,第六代至强平台能够将内存访问延时降低一半,从而进一步提升训练速度。这些优势使得天翼云超聚合计算服务器成为内存密集型应用的理想选择。
天翼云弹性高性能计算(E-HPC)
经过多年打磨,天翼云E-HPC弹性高性能计算平台凭借卓越的计算能力与灵活的弹性扩展,在汽车制造、芯片设计、生物信息等领域,逐渐成为解决复杂计算问题的首选平台。借助最新的GNR处理器,E-HPC平台显著提升了计算密度和性能表现。
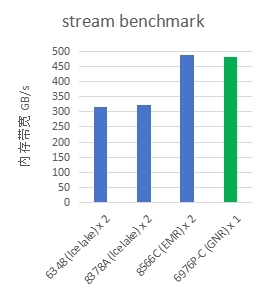
在stream基准测试中,配备GNR处理器的E-HPC平台凭借更多的内存通道和更高的内存频率,在6400 MT/s DDR5内存环境下,单路实测内存带宽达到约500GB/s,相比上一代EMR获得两倍的性能提升,较第三代IceLake实现了三倍的性能提升。预计在8800 MT/s MRDIMM配置下,双路系统有望实现1.4TB/s。这大幅提升了HPC中以科学计算为代表的内存带宽敏感型应用的计算效率。
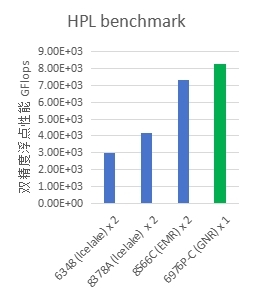
在HPL基准测试中,实测单路GNR处理器双精度浮点性能接近8.3 TFlops,超越了上一代EMR双路的性能,刷新了CPU性能的新纪录。澎湃的算力极大提升了神经网络训练、蒙特卡罗模拟和图像处理等计算密集型任务的执行效率。
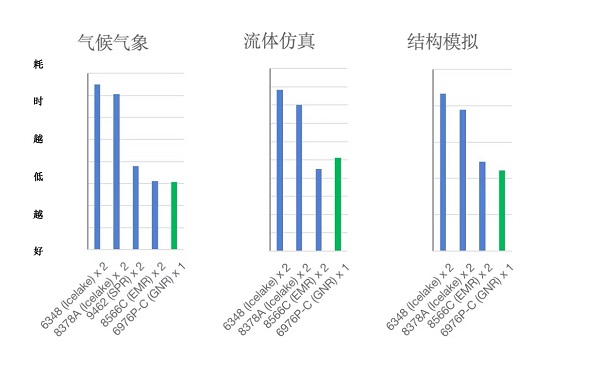
在多个主流HPC应用领域,以气候气象、流体仿真和结构模拟为例,GNR处理器凭借其强大的单芯片核数与内存带宽优势,在单路测试环境中展现出与双路EMR 相媲美的计算效率,这意味着在双路GNR处理器配置下,计算性能和资源利用率将相较于上一代大幅提升,甚至有望实现翻倍增长。通过这一评测结果,天翼云E-HPC平台可以更清晰地预测未来在实际生产环境中的表现,为进一步优化性能、降低成本、增强计算密度提供了可靠的基础。
未来,我们将继续深入性能优化,涵盖更多HPC应用场景,如基因组学分析、材料科学模拟和高频金融建模等,以进一步验证GNR处理器在各类复杂计算任务中的优异表现。我们期待这些测试结果为行业用户提供更多优化方案,并受到更多行业客户的青睐。
合作与前瞻
天翼云将在人工智能、大数据分析和企业级应用等领域展开深度探索,不断优化天翼云弹性计算性能、数据处理能力和能效表现,并携手产业链伙伴通过联合研发、技术支持和资源共享的方式,共同推动新一代云技术的应用普及,满足日益增长的市场需求,并为各行业的数字化转型赋能。
「免责声明」:以上页面展示信息由第三方发布,目的在于传播更多信息,与本网站立场无关。我们不保证该信息(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关信息并未经过本网站证实,不对您构成任何投资建议,据此操作,风险自担,以上网页呈现的图片均为自发上传,如发生图片侵权行为与我们无关,如有请直接微信联系g1002718958。
